Clustering
Xapiand is built to be always available and to scale with your needs. Scale can come from buying bigger servers (vertical scale, or scaling up) or from buying more servers (horizontal scale, or scaling out).
While Xapiand can benefit from more-powerful hardware, vertical scale has its limits. Real scalability comes from horizontal scale: the ability to add more nodes to the cluster and to spread load and reliability between them.
With most databases, scaling horizontally usually requires a major overhaul of your application to take advantage of these extra boxes. In contrast, Xapiand is distributed by nature: it knows how to manage multiple nodes to provide scale and high availability. This also means that your application doesn’t need to care about it.
What is a Cluster?
A node is a running instance of Xapiand, while a cluster consists of one or more nodes running under the same cluster name that are working together to share their data and workload.
One node in the cluster is elected to be the master node, which is in charge of managing cluster-wide changes like creating or deleting an index, or adding or removing a node from the cluster. The master node does not need to be involved in document-level changes or searches, which means that having just one master node will not become a bottleneck as traffic grows. Any node can become the master.
As users, we can talk to any node in the cluster, including the master node. Every node knows where each document lives and can forward our request directly to the nodes that hold the data we are interested in. Whichever node we talk to manages the process of gathering the response from the node or nodes holding the data and returning the final response to the client. It is all managed transparently by Xapiand.
An Empty Cluster
If we start a single node, with no data and no indices, our cluster, a cluster with one empty node, looks like this:

Our example cluster has only one node, so it performs the master role.
Add an Index
To add data to Xapiand, we need an index, a place to store related data. In reality, an index is just a logical namespace that points to one or more physical shards.
A shard is a low-level worker unit that holds just a slice of all the data in the index. Our documents are stored and indexed in shards, but our applications don’t talk to them directly. Instead, they talk to an index.
Shards are how Xapiand distributes data around your cluster. Think of shards as containers for data. Documents are stored in shards, and shards are allocated to nodes in your cluster. As your cluster grows or shrinks, Xapiand will automatically migrate shards between nodes so that the cluster remains balanced.
A shard can be either a primary shard or a replica shard. Each document in your index belongs to a single primary shard, so the number of primary shards that you have determines the maximum amount of data that your index can hold.
A replica shard is just a copy of a primary shard. Replicas are used to provide redundant copies of your data to protect against hardware failure, and to serve read requests like searching or retrieving a document.
The number of primary shards in an index is fixed at the time that an index is created, but the number of replica shards can be changed at any time.
Let’s create an index called blogs in our empty one-node cluster. By default, indices are assigned five primary shards, but for the purpose of this demonstration, we’ll assign just three primary shards and one replica (one replica of every primary shard):
PUT /blogs/
{
"_settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}Our cluster now looks like a single-node cluster with an index. All three
primary shards have been allocated to Node 1:

Currently, our cluster is fully functional but at risk of data loss in case of hardware failure.
Add Failover
Running a single node means that you have a single point of failure) there is no redundancy. Fortunately, all we need to do to protect ourselves from data loss is to start another node.
If we start a second node, our cluster would look like a two-node cluster with all primary and replica shards allocated:
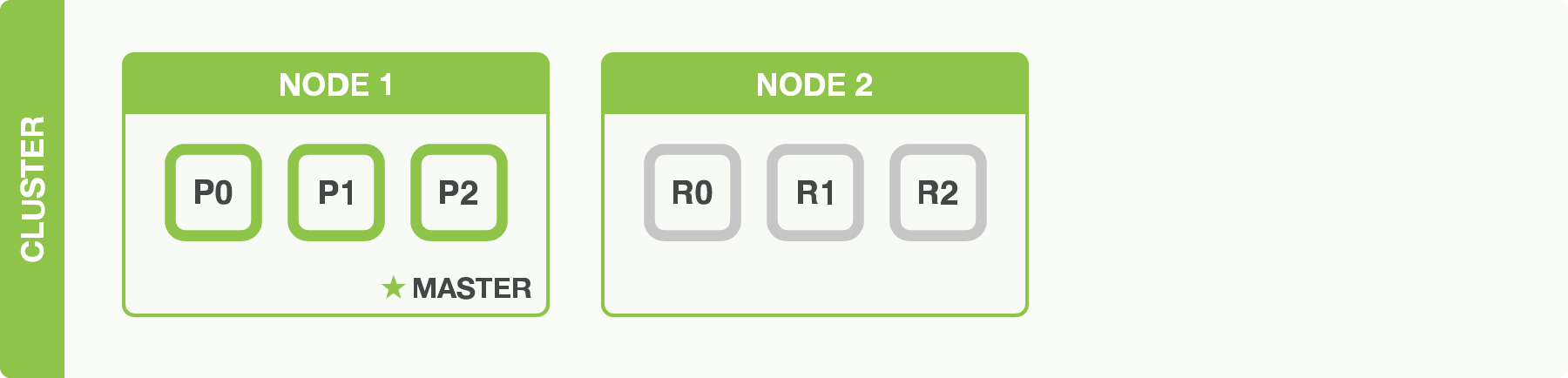
The second node has joined the cluster, and three replica shards have been allocated to it, one for each primary shard. That means that we can lose either node, and all of our data will be intact.
Any newly indexed document will first be stored on a primary shard, and then copied to the associated replica shard(s). This ensures that our document can be retrieved from a primary shard or from any of its replicas.
Scaling Out
Unimplemented Feature!
Node reorganization during scaling out is not yet implemented.
Pull requests are welcome!
If we start a third node, our cluster reorganizes itself to look like a three-node cluster with shards reallocated to spread the load:
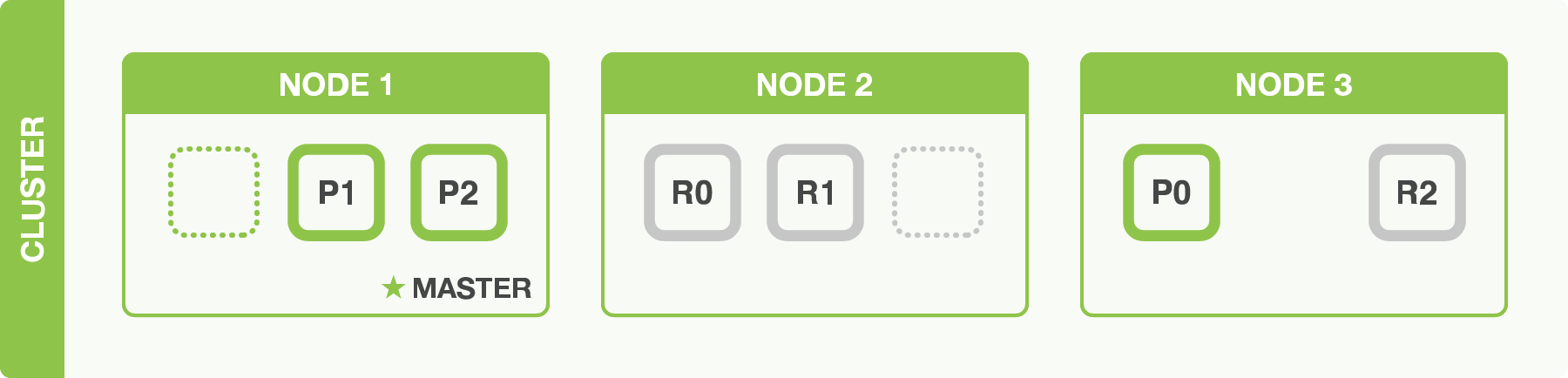
One shard each from Node 1 and Node 2 have moved to the new Node 3, and we have
two shards per node, instead of three. This means that the hardware resources
(CPU, RAM, I/O) of each node are being shared among fewer shards, allowing
each shard to perform better.
The number of primary shards is fixed at the moment an index is created. Effectively, that number defines the maximum amount of data that can be stored in the index (the actual number depends on your data, your hardware and your use case); however, read requests (searches or document retrieval) can be handled by a primary or a replica shard, so the more copies of data that you have, the more search throughput you can handle.
The number of replica shards can be changed dynamically on a live cluster,
allowing us to scale up or down as demand requires. Let’s increase the number
of replicas from the default of 1 to 2:
PUT /blogs/
{
"_settings" : {
"number_of_replicas" : 2
}
}After increasing the number of replicas to 2, the blogs index now has nine shards (three primaries and six replicas). This means that we can scale out to a total of nine nodes, again with one shard per node. This would allow us to triple search performance compared to our original three-node cluster:
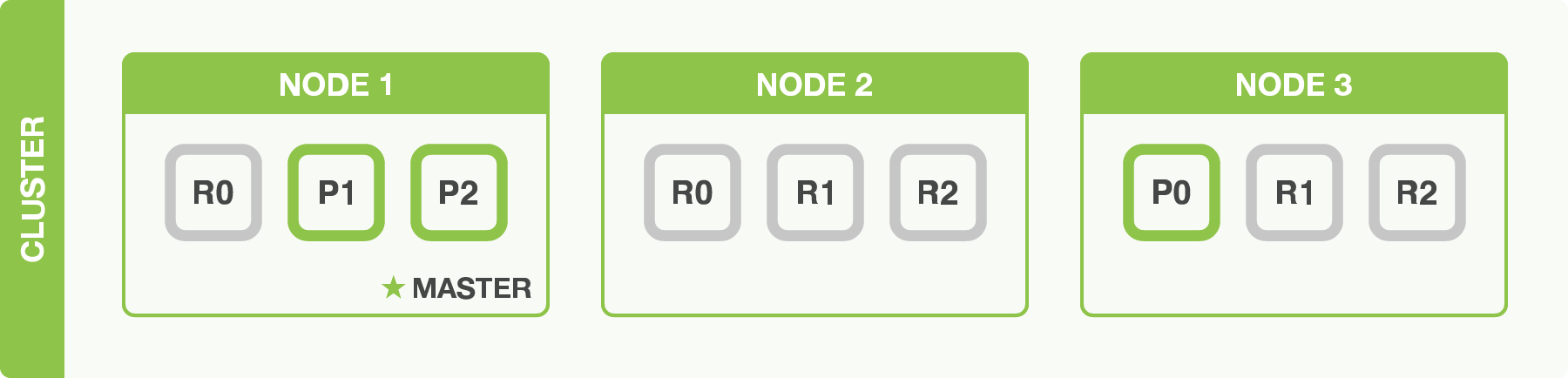
You need to add hardware to increase throughput
Just having more replica shards on the same number of nodes doesn’t
increase our performance at all because each shard has access to a smaller
fraction of its node’s resources.
Coping with Failure
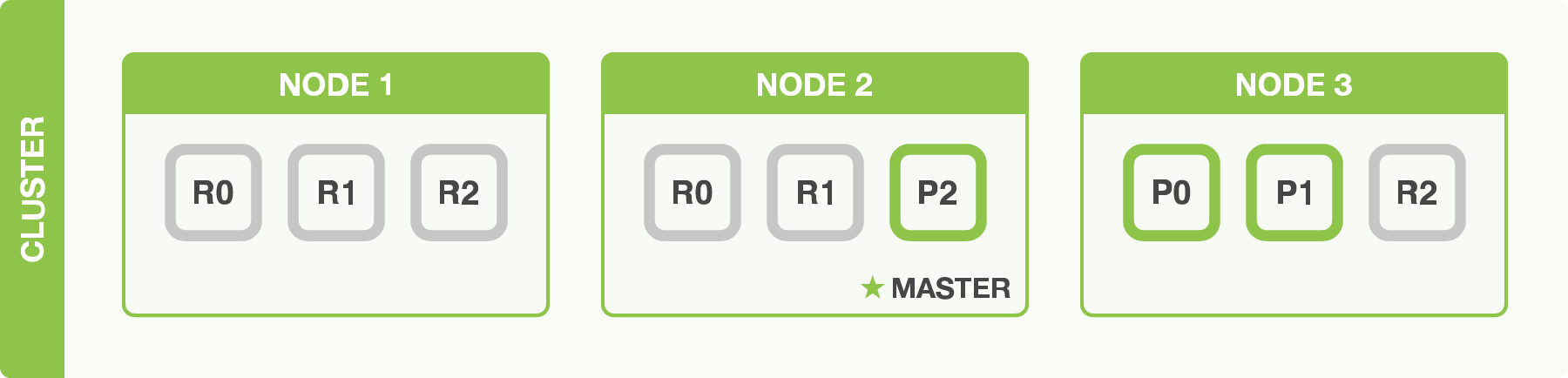
We’ve said that Xapiand can cope when nodes fail, so let’s go ahead and try it out. Let’s look at our cluster after killing node one:
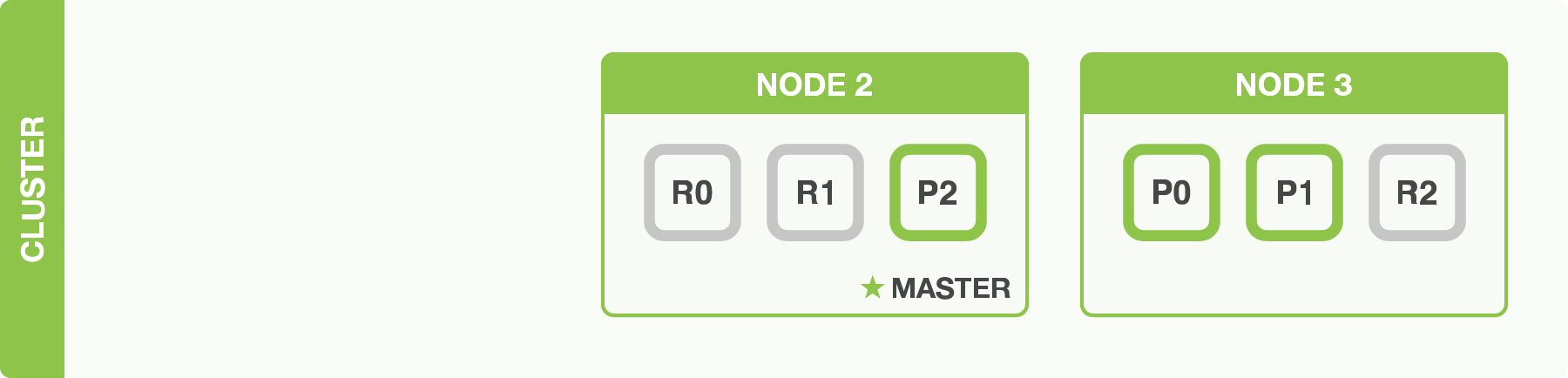
The node we killed was the master node. A cluster must have a master node in
order to function correctly, so the first thing that happened was that the
nodes elected a new master: Node 2.
Primary shards P1 and P2 were lost when we killed Node 1, and our index
cannot function properly if it is missing primary shards.
Unimplemented Feature!
Promoting a replica shard to a primary shard is not yet implemented.
Pull requests are welcome!
Fortunately, a complete copy of the two lost primary shards exists on other
nodes, so the first thing that the new master node did was to promote the
replicas of these shards on Node 2 and Node 3 to be primaries.
If we restart Node 1, The cluster after restarting node one would be able
to allocate the missing replica shards:
If Node 1 still has copies of the old shards, it will try to reuse them,
copying over from the primary shard only the missing parts that have changed in
the meantime.